My adventure in designing API keys
Vjaylakshman K • April 12, 2026
Hello everyone, It has been quite a long time since my last blog, the last couple of months had been very busy and packed with a lot of work so I barely had much time to write blogs. Time runs so fast that the last time when I wrote a blog I was still a DevOps Engineer and now I am a Product Developer lol.
This time we are going to look into API keys, of which I found very few articles that explained how it worked, So I thought why not write a blog on whatever I have learnt from my research! This blog focuses on the API key creation and design.
API keys
API keys are exactly what they sound like. A token to access the API by authenticating and authorizing yourself without the need for sessions. These are used for public APIs that allow users to directly call the endpoints and get their response directly.
Sounds simple enough? so all it is, is just a string that allows you to authenticate yourself! But I was not happy with this answer, so I decided to dig further. The reason is very simple, I am just curious and love to research a topic thoroughly before implementing.
Format of API Keys
API keys are usually formatted in this way.
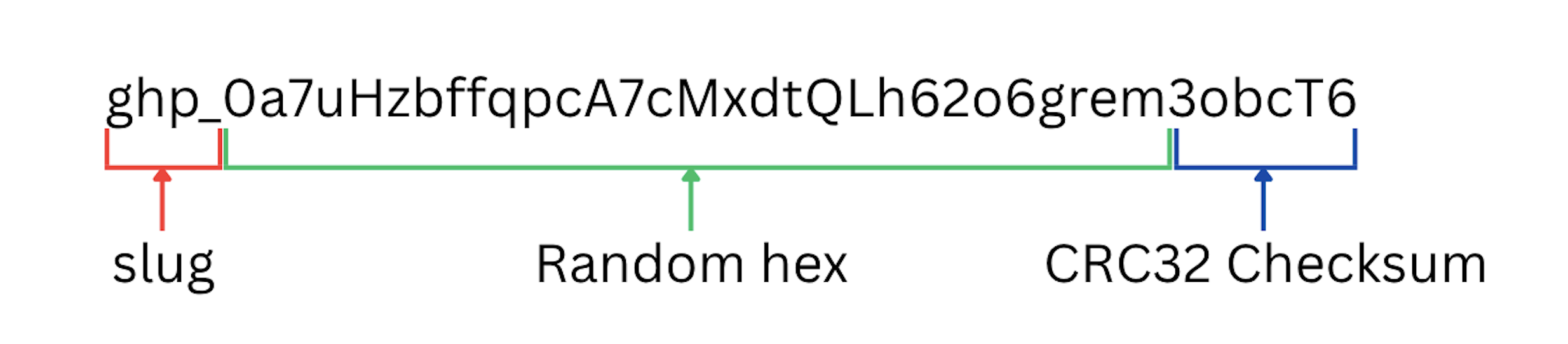
The prefix is just extra metadata that is useful for the end user as well as the developer to figure out the kind of API key it is. For example github uses the gh(o|p) prefix, stripe uses sk_live or sk_test prefix.
The next few characters in my example key is just random hex string whose length could vary across implementations. And at last either clubbed together with the hex string or separated by an '_' is the checksum. The reason behind having a checksum is that it allows you to verify first whether this API key is even valid before hitting the DB, since either there could be a mistype by the user or maybe a missed character.
This is the most widely followed industry format for API keys. There can be special cases such as when some part of the prefix of hex characters can be just a unique hex ID of a single account. I will further explain the reason behind why this is done.
These API keys are then hashed and stored in the DB, therefore once created, it has to be copied or it's lost forever. This makes it secure since it's now hashed, just like a password, so the contents are unknown to everyone who has access to the system. This is why most of the systems that support API keys, ask you to copy it after creation.
Some APIs store just the first few characters of the API key to help you distinguish between multiple API keys easily. Further you can add permissions, API call logging per key etc.. the implementation is pretty straightforward.
The hurdle I faced
I am working on a multi tenant based system with sharding. The public API has to be integrated into the existing backend workflow, and all the user data is stored in different shards and so are the API key hashes and related tables.
The problem I encountered was how can I route the request to the correct DB Shard? since before we had session cookies that had the account IDs which can be used to find out which shard the account belongs to based on the metashard's mapping tables.
So I had to do a bit of research, trying to manage this mapping over time and what could be the approaches through which I can fix the problem I have at hand.
Approach - 1 - Just map the hashes to the account ID in the metashard
This is the default approach, just take the hashes of the API keys and directly map it to the account ID. It was good enough, the performance wasn't that bad when I tested it with around 20 Million records, where it gave a really good read and write speeds.
But I was not really happy with it, since it felt that I was repeating myself here, why do we have to store the entire hash when all we need is to map the API key to the account. Therefore, I looked into more approaches apart from this.
Approach - 2 - The prefix approach
Let us say that we assign a company an unique API key prefix, and whenever they create an API key, the first few characters of the hex will always be the unique prefix and the rest random hex characters, a very sensible and easy approach to solving this issue.
Then this unique API key prefix can be stored in a table in the metashard and mapped to the account id, then this ID can be used to find out the shard ID. This is also comparable in performance compared to the 1st Approach, but the sizes of the indices and the overall table memory is reduced.
This comes at the cost of making the prefix predictable and increasing the chances of collision of hashes, but it is very miniscule that it can be overlooked. I didn't proceed with this approach since I don't want the API keys to have any info regarding the account, but hey it is all just a matter of preference and opinion.
Approach - 3 - Encode the Hash?
I was trying to figure out more approaches myself along with Claude, I came up with the base idea of what if we use another encoding algorithm such as base64 to encode the string and use the first few characters to map it to the account, since base64 is always different for different hashes.
I initially worked out with a working POC of a base62 approach which generated a 10 character encoded string which gave really good results, then tried with a base70 approach where I added 8 more symbols (API key safe) to the existing 62 characters and reduced it to 8 character encoded strings, which not only reduced the size but also the lookup times.
But this is when I found out that the test bench had a very critical flaw. When comparing to the initial hash to account ID approach, I measured the direct hash to account ID mapping with the TCP connection time thus it gave inflated values for the full SHA appraoch since it was measured first. I had to correct myself and I retested.
(RTT = round-trip time for the request; PG med = median Postgres time in my benchmark.) All the tests that are run in this blog are done for 1 Million records with 1000 test API keys and 100 runs each and the hash/encoded string column is indexed using B-Tree
| Approach | RTT med (ms) | PG med (ms) |
|---|---|---|
| Full SHA-256 (64 char) | 0.222 | 0.006 |
| Base-62 x 10 | 0.779 | 0.044 |
| Base-70 x 8 | 0.330 | 0.005 |
My eyes could not believe the tests, I looked into the test scripts, re-ran the tests more to verify whether this was not a fluke and I was confused so much.
After much digging into the cause behind it, I found the two reasons behind this
1.) B-Tree is very efficient for strings as well: B tree index in PostgreSQL is good for any data as long as they are sortable. My assumption that reducing the size of the string will increase the lookup time is baseless, since the key hashes are strings that can be sorted, and if they can be sorted they can definitely be easily looked up in the Database just like any other sortable values like Integers.
Then even if the SHA hash differs and is big, it still is just a node in the tree that can be looked up easily. This is why the SHA performed better.
2.) BigInt Operations in Javascript are slow: The Base-62 and Base-70 conversion was done via repeated BigInt division
const hash = crypto.createHash('sha256').update(input).digest('hex');
let num = BigInt('0x' + hash); // ← convert 64-char hex string to a BigInt
let result = '';
while (num > 0n) { // ← repeated BigInt division in a loop
result = BASE62[Number(num % 62n)] + result;
num /= 62n;
}
return result.slice(0, length);
The reason being that BigInts use arbitrary-precision math implemented in software, unlike normal number types that map to hardware-native floats and integers. That software path tends to allocate more on the heap than a simple hash comparison would.
Another issue is that not just am I doing one of the slowest operations using BigInt but also 43 times, despite only needing the first 10 or 8 characters, this resulted in the worse performance overall compared to just simple hash.
Final Approach - SHAKE hash algorithm
The final algorithm that I chose is the newest family of SHA algorithm, SHA3 and a variant of it called SHAKE. SHA3 algorithm was a bit different from the traditional SHA2 (SHA-256 etc) where instead of trying to create fixed size blocks based on the type of algorithm, here we try to absorb the entire text into a 1600 unit block like a sponge.
I tried digging into the implementation, and understood some of it. I will let the existing articles explain this since they do a better job than I would here.
This sponge style algorithm allows us to get fixed size outputs of any length, you can just squeeze out the bits you need and nothing more, similar to the prefix approach but now I don't do the full generate and slice approach. Therefore this was a better approach than my previous encoding style approach and the overall performance was great as well!
Gave the same amount of performance just like the Full SHA hash but now both computation cost and the index size is reduced. The representation is now base64url instead of hex (only 16 characters) thus increases the overall possibility of API keys being created.
(Same column meanings as the first benchmark table.)
| Approach | RTT med | PG med |
|---|---|---|
| SHAKE256 32B → b64url | 0.189 | 0.005 |
| SHAKE256 32B b64url prefix 8 | 0.113 | 0.004 |
| SHAKE256 32B b64url prefix 10 | 0.185 | 0.005 |
| SHAKE256 32B b64url prefix 12 | 0.120 | 0.004 |
| SHAKE256 6B → b64url (8 chars) | 0.146 | 0.005 |
| SHAKE256 7B → b64url (10 chars) | 0.150 | 0.005 |
| SHAKE256 9B → b64url (12 chars) | 0.172 | 0.005 |
I didn't base the decision only on performance but also on the possibility of hash collisions, which can be estimated using the birthday paradox.
For 8 characters there can be around 281 Trillion possibilities but 10 characters had around 72 Quintillion possibilities, the chances of collision happening are near zero for 10 characters, therefore I went with the 10 character encoding of the generated hash.
Conclusion
Having to work on an actual problem in real life taught me about how much mistakes I make and also the many assumptions I do, it has helped me figure out the ways in which I can increase my clarity in a problem and how to make proper POC and research about it.
This was such a good learning experience for me about not just API key design but also how B tree index works for strings, how hash algorithm works and also how slow BigInt operations can be.
At the end of the day we have an API key system that is working :D Thanks for reading this blog, I hope you all have a nice day :)